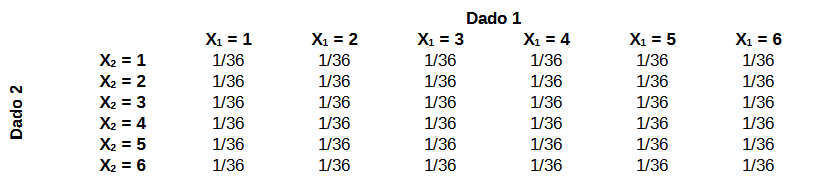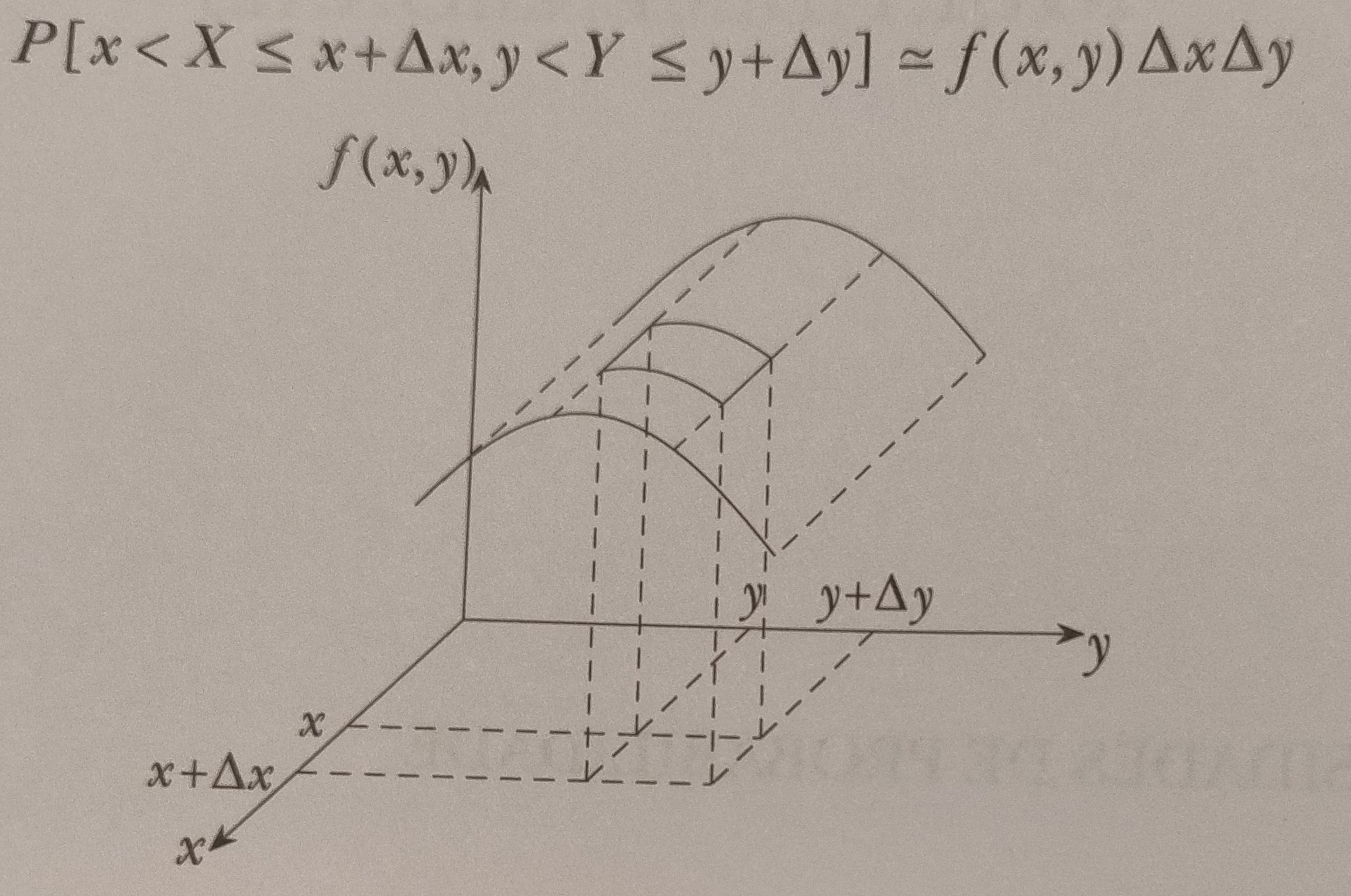Definição (Rolla (2021)) Um vetor aleatório\((X_1, ..., X_p)\) é uma função \(X: \Omega \rightarrow \mathbb{R}^p\) tal que cada coordenada \(X_i\) é uma variável aleatória.
Importante destacar que a notação para vetor aleatório pode variar de acordo com o autor. Podemos encontrar a notação como \(\textbf{X}\) (isto é, em negrito conforme Magalhães (2006)), \(\overset{\sim}{X}\) ou, ainda, \(\underset{\sim}{X}\) (James (2023)).
Vetores Aleatórios Discretos
Distribuições de Probabilidade
Definição A distribuição de probabilidade do vetor aleatório \(\textbf{X} = (X_1, X_2, ..., X_p)\) é uma tabela que associa a cada valor \((x_1, x_2, ..., x_p)\) desse vetor sua correspondente probabilidade \(P([X_1 = x_1, X_2 = x_2, ..., X_p = x_p])\). Ela é denominada também distribuição conjunta de \(X_1, X_2, ..., X_p\).
Observemos que a notação \([X_1 = x_1, X_2 = x_2, ..., X_p = x_p]\) representa a intersecção dos eventos \([X_1 = x_1], [X_2 = x_2], ..., [X_p = x_p]\) ou seja,
Uma notação alternativa para \(P([X_1 = x_1, X_2 = x_2, ..., X_p = x_p])\) é \(P(X_1 = x_1, X_2 = x_2, ..., X_p = x_p)\).
Exemplo Lançamento de dois dados honestos. Seja \(X_1\) o valor da face do primeiro dado e \(X_2\) o valor da face do segundo dado a distribuição conjunta do vetor aleatório \((X_1, X_2)\) é dada por
Distribuição Conjunta de Dois Dados Honestos
Exemplo Lançamento de um dado e uma moeda, ambos honestos. Seja \(X\) o valor da face do primeiro dado e \(Y\) a variável aleatória da moeda sendo \(Y = 1\) se “cara” e \(Y = 0\) se “coroa”. Então, a distribuição conjunta do vetor aleatório \((X, Y)\) é dada por
Distribuição Conjunta de Um Dado e Uma Moeda Honestos
Definição (Dantas (2013)) A função de distribuição do par de variáveis aleatórias discretas \((X,Y)\) é dada por:
Uma notação alternativa para \(F(x,y)\) é \(F_{X,Y}(x,y)\).
Distribuições Marginais
A distribuição marginal de uma variável aleatória específica é dada ao somarmos as probabilidades “varrendo” todo o intervalo de todas as demais variáveis do vetor aleatório. Por exemplo, assuma que em um vetor aleatório \((X,Y)\), \(X\) assume os valores \(x_1, x_2, ..., x_n\) enquanto \(Y\) assume os valores \(y_1, y_2, ..., y_m\). Então, a ditribuição marginal de X é dada por
Analogamente, para obter a marginal de qualquer subconjunto de \((X_1, X_2, ..., X_p)\), fazemos o somatório percorrendo o subconjunto complementar. Por exemplo, para a marginal de \((X_1, X_2)\), tem-se:
Definição As variáveis aleatórias \(X_1, X_2, ..., X_p\) são ditas independentes se para todos os elementos \(x_1, x_2, ..., x_p\) das mesmas tivermos:
Definição A distribuição condicional de \(Y\) dado \(X\) associa a cada valor \(x\) de \(X\) uma distribuição de probabilidade sobre os valores de \(Y\), da seguinte maneira:
\[
P(Y = x | X = x) = \frac{P(X = x, Y = y)}{P(X = x)}
\]
Note que isso se refere à distribuição condicional de \(Y\) dado \(X\), estamos nos referindo ao conjunto de todas as distribuições condicionais associadas a cada um dos valores de \(X\).
Vetores Aleatórios Contínuos
Distribuições de Probabilidade
Definição Uma função \(f(x,y)\) definida para \(- \infty < x < + \infty\), \(- \infty < y < + \infty\), não-negativa e satisfazendo a condição
é denominada uma função densidade de probabilidade da variável aleatória bidimensional \((X,Y)\) se para todo o subconjunto \(B\) de pontos do \(\mathbb{R}^2\) tivermos:
\[
P((X,Y) \in B) = \int\int_{B}f(x,y)dxdy
\]
Segundo Dantas (2013), a interpretação da função densidade de probabilidade no caso bidimensional é a seguinte: seja \((x,y)\) um ponto do plano e consideremos um retângulo de lados \(\Delta x\) e \(\Delta y\) construído a partir do ponto \((x,y)\). A probabilidade de que \((X,Y)\) pertença a esse retângulo é aproximadamente igual ao volume do paralelepípedo de lados \(\Delta x\) e \(\Delta y\) e cuja altura é \(f(x,y)\), ou seja,
Construção de probabilidade de uma distribuição conjunta bidimensional (Extraído de Dantas (2013))
Abaixo, seguem alguns exemplos visuais tridimensionais:
Exemplo Função bidimensional com área destacada entre dois valores de cada variável:
Suponha a densidade
\[
f(x,y) = 9x^2y^2, \quad 0 \le x,y \le 1,
\]
Suponha o cálculo de probabilidade do tipo:
\[
P(c \le X \le d, \; e \le Y \le f) \;=\;
\int_c^d \int_e^f 9x^2 y^2 \, dy \, dx.
\]
Essa integral tem solução fechada:
\[
P = (d^3 - c^3)\,(f^3 - e^3).
\]
Vamos calcular e ilustrar o valor da probabilidade \(P(0.2 \le X \le 0.6, 0.3 \le Y \le 0.8)\):
Probabilidade P(0.20 <= X <= 0.60, 0.30 <= Y <= 0.80) = 0.1009
Mostrar Código
# --- Grid para visualização ---x_seq <-seq(0, 1, length.out =80)y_seq <-seq(0, 1, length.out =80)Z <-outer(x_seq, y_seq, f_xy)# Máscara região do intervalomask_region <-outer(x_seq, y_seq, function(x, y) (x >= c1 & x <= d1 & y >= e1 & y <= f1))# --- Gráfico 3D ---p3d <-plot_ly(showscale =FALSE) %>%add_surface(x = x_seq, y = y_seq, z = Z,opacity =0.6, name ="densidade") %>%add_surface(x = x_seq, y = y_seq,z =ifelse(mask_region, Z, NA),opacity =1.0, name ="região do intervalo") %>%layout(title ="Distribuição f(x,y) = 9x²y² com intervalo destacado",scene =list(xaxis =list(title ="X"),yaxis =list(title ="Y"),zaxis =list(title ="densidade")))p3d
Exemplo Normal Bivariada
Mostrar Código
# --- Dependências (instalar se não estiverem disponíveis) ---pacotes <-c("mvtnorm", "plotly")nao_instalados <- pacotes[!pacotes %in%installed.packages()[, "Package"]]if(length(nao_instalados)) install.packages(nao_instalados, repos ="https://cloud.r-project.org")library(mvtnorm) # para dmvnormlibrary(plotly) # para superfície 3D interativa# --- Parâmetros da normal bivariada ---mu <-c(0, 0) # vetor de médiasSigma <-matrix(c(1.0, 0.6, # matriz de covariância com correlação0.6, 1.0), ncol=2)# --- Grade onde avaliamos a densidade ---x_seq <-seq(-3, 3, length.out =121)y_seq <-seq(-3, 3, length.out =121)grade <-expand.grid(x = x_seq, y = y_seq)# Avaliar densidade bivariada na gradedens <-dmvnorm(grade, mean = mu, sigma = Sigma)z_mat <-matrix(dens, nrow =length(x_seq), ncol =length(y_seq))# --- Superfície 3D interativa com plotly ---p <-plot_ly(x = x_seq, y = y_seq, z =~z_mat, showscale =TRUE) %>%add_surface() %>%layout(title ="Densidade Normal Bivariada (interativa)",scene =list(xaxis =list(title ="X1"),yaxis =list(title ="X2"),zaxis =list(title ="Densidade") ))# Aparece no Viewer do RStudio ou no navegadorp
Definição (Dantas (2013)) A função de distribuição de uma variável aleatória bidimensional \((X,Y)\) é dada por:
\[
F(x,y) = P(X \le x, Y \le y), \quad x \in \mathbb{R}, y \in \mathbb{R}
\]
Uma notação alternativa para \(F(x,y)\) é \(F_{X,Y}(x,y)\).
No caso de variáveis aleatórias contínuas \(X\) e \(Y\), a probabilidade do evento \([X \le x, Y \le, y]\) é igual ao valor da integral da densidade conjunta de \((X, Y)\) no conjunto \(B = [X \le x, Y \le, y]\)
Dada a densidade conjunta das variáveis \(X\) e \(Y\), podemos determinar as densidades de \(X\) e de \(Y\) isoladamente. Essas densidades são chamadas de densidades marginais \(f_X(x)\) e \(f_Y(x)\), respectivamente. Elas são obtidas através da seguinte maneira:
Para o caso multivariado, por exemplo para o vetor aleatório \((X_1, X_2, ..., X_p)\) para obter uma marginal em específico, por exemplo, \(X_1\) integramos em relação à todas às demais, isto é:
Definição As variáveis aleatórias \(X\) e \(Y\), cuja densidade conjunta é \(f(x,y)\), para \(x,y \in \mathbb{R}\), e cujas densidades marginais são denotadas \(f_X(x)\) e \(f_Y(y)\), são ditas independentes se para todo o par de valores \((x,y)\) tivermos
Definição A distribuição condicional de \(Y\) dado \(X\) associa a cada valor \(x\) de \(X\) uma distribuição de probabilidade sobre os valores de \(Y\), da seguinte maneira:
\[
f_{Y|X}(y|x) = \frac{f_{X,Y}(x,y)}{f_X(x)}
\]
Note que isso se refere à distribuição condicional de \(Y\) dado \(X\), estamos nos referindo ao conjunto de todas as distribuições condicionais associadas a cada um dos valores de \(X\).
Referências
Dantas, C. A. B. 2013. Probabilidade: Um Curso Introdutório Vol. 10. EDUSP.
James, Barry R. 2023. Probabilidade: um curso em nível intermediário. 5.ª ed. IMPA.
Magalhães, M. N. 2006. Probabilidade e Variáveis Aleatórias. 3.ª ed. Edusp.